Parallel computing is covered in some detail in a companion course, Math 687A Advanced Scientific Computing , however, here we will limit ourselves to the 4 most important concepts in good parallel program design:
| Concurrency | Using many processors to accomplish a task |
| Scalability | Good program design should run on any number of processors and should not be penalized in performance for doing so. |
| Locality | Should exploit the local nature of stored information in order to optimize speed. |
| Modularity | Modular program design makes codes more portable and easier to interface and maintain. |
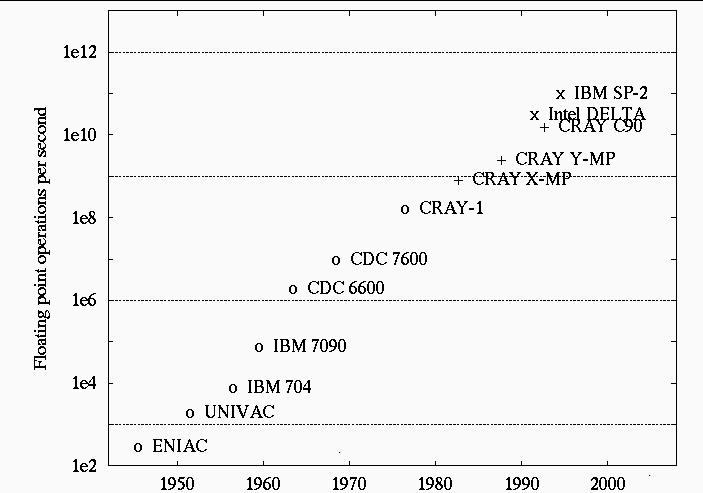
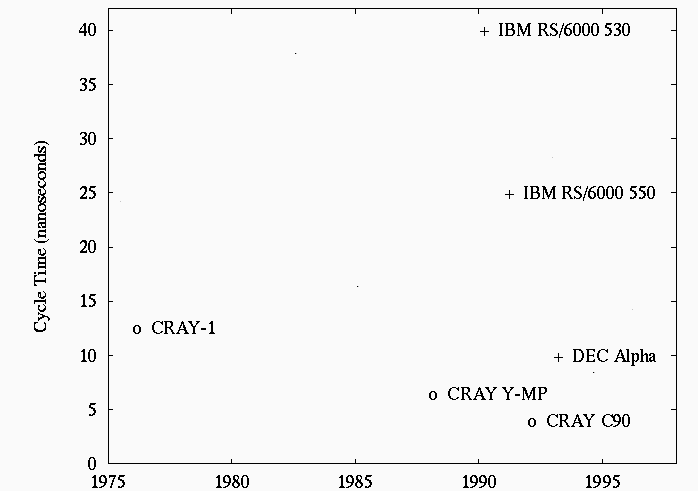
The speed in which a problem is solved depends on the time required to execute a single operation and on the number of concurrent operations. While computers are getting faster, it is clear that concurrency needs to be exploited to attain greater speeds: the speed of a basic operation cannot exceed the clock cycle . Even if a machine's information traveled at the fastest speed, the speed of light, the time required for a basic operation to take place would be T=D/c, where D is the distance on the chip that a signal must travel, and c is the speed of light. Since D is proportional to A^(1/2), where A is the surface area on a chip, the only way to decrease the time of computation is by making chips smaller. For example, to increase the speed by 2 would require that the chip be smaller by 4.
A defining attribute of parallel machines is that local access to memory is faster than remote access, in a ratio of 10:1 to 1000:1. So locality is very desirable, in addition to concurrency and scalability.
Parallel programming and architecture is necessarily complex due to
synchronization requirements and inter-node communication. Abstraction
is essential in order to design robust algorithms. An important vehicle
for abstraction is modularity . Abstraction is the primary
motivation for developing object oriented languages, which by design
have a certain amount of modularity already in place.
Modularity is also a good design
practice, since it tends to produce codes that can be easily diagnozed
and linked to other programs. In addition, if codes are made portable,
they will tend to run on many types of computers without requiring large
changes in the code. The following is a typical parallel computing
algorithm:
In summary, four important aspects of parallel computing are:
MIMD (Multiple instruction multiple data) come in two basic
types: Multicomputer Architecture and Multiprocessor
Architecture .
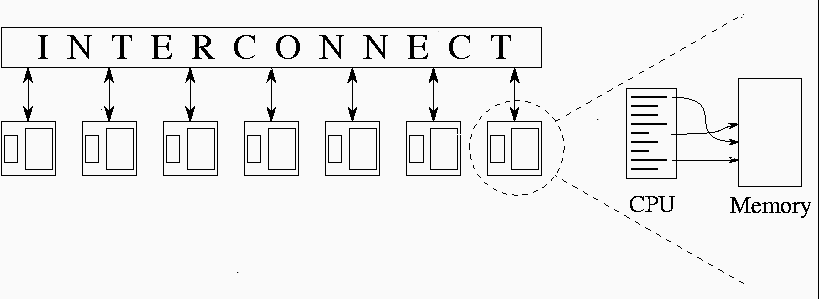
The multicomputer (distributed memory device)
is such that each node is a processor and
can execute a separate
stream of instructions on its own local data. Distributed memory means
that data is distributed among many processors, rather than held in some
central memory device. Here the cost of sending/receiving is then
dependent on the node location and on network traffic. Some machines of
this type are: IBM-SP, Cray 3TD, Meiko CS-2, nCUBE.
Schematic
of a multicomputer
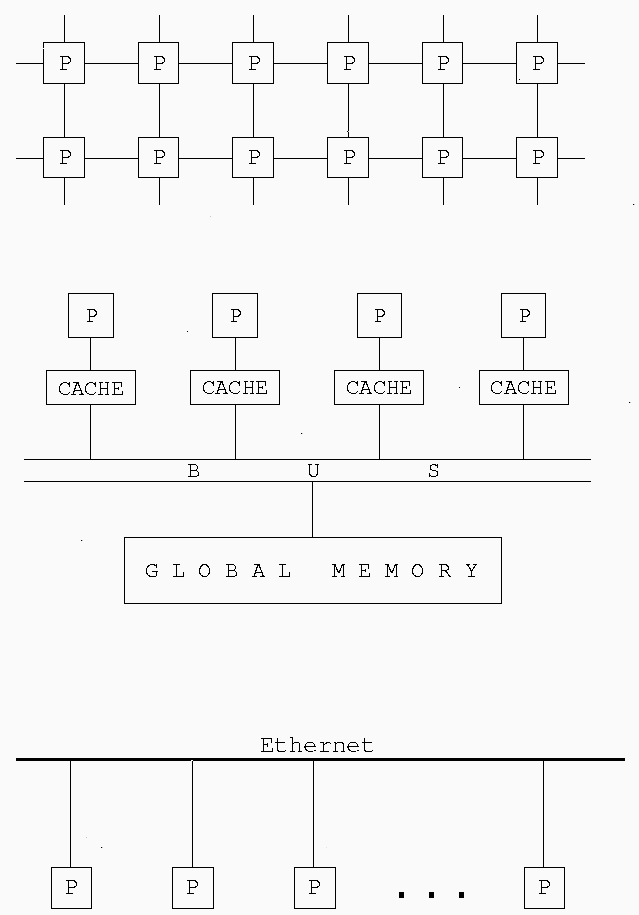
The multiprocessor (shared memory device)
is such that all nodes share a common centrally
located memory device. Here, cache (the smallest and most local form of
memory as far as the CPU is concerned) is exploited to load frequently
used data on all of the processors. Examples are SGI Power Challenge,
Sequent Symmetry.
Comparison of a distributed memory machine, shared memory machine and
local area network
SIMD (single instruction multiple data): all processors execute
the same instruction stream on a different piece of data. It has the
potential of reducing considerably the complexity of both hardware and
software, but it is usually appropriate only for specific problems,
i.e. such things are specific image processing, certain numerical
calculations. Examples are MasPar MP, Thinking Machines CM1. These
machines are not as popular as they once were.
Parallel Machine Models
A Processor is composed of a CPU and its memory storage
device. This is the von Neumann computer.
Parallel Networks
Fast networks that are commonly used are:
Parallel Computing Software
This software offers a minimum instruction set with which parallel codes
to run on MIMD machines can be built. The most widely used ones are
MPI, p4, PVM.
Further Sources and Tools
{kind=link}
{kind=link}
{kind=link}
{kind=link}